Data Preprocessing for Machine Learning
Prepare your datasets by handling missing values, encoding categorical variables, and scaling numerical features through a guided step-by-step interface.
Get StartedFeature Overview
Tool Capabilities
Essential preprocessing functions available through our interface.
3
Problem Types
Supports regression, classification, and time series
CSV
File Formats
Standard format for data upload
Auto
Target Detection
Automatic target column identification
Yes
Industry Recognition
Automatically identifies dataset domain
Data Transformation
Convert Raw Data to ML-Ready Format
Our platform handles essential preprocessing tasks including imputation, encoding, and scaling. Select your dataset, choose a problem type, specify your target column, and set preprocessing parameters to prepare your data for machine learning.
Get Started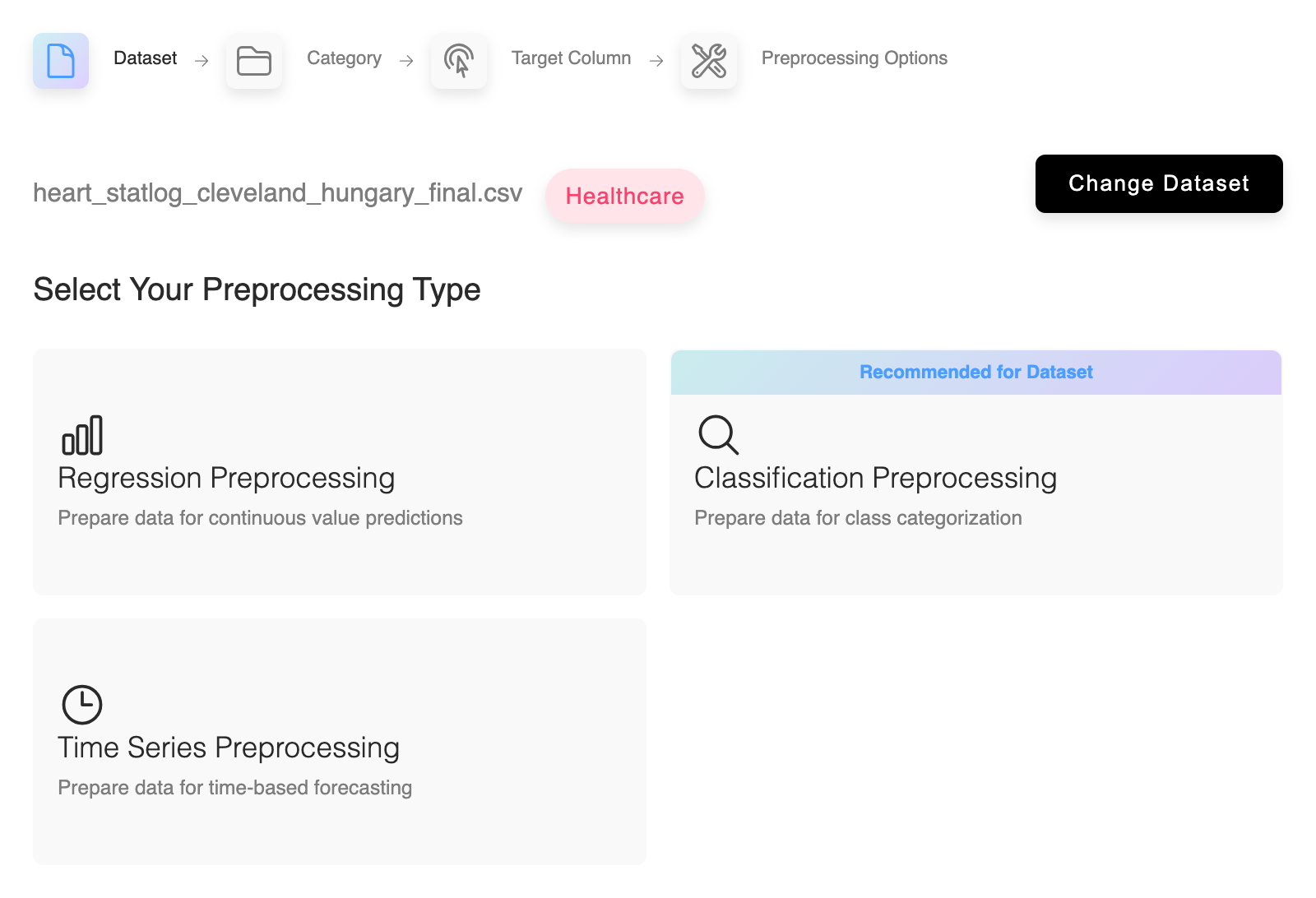
Core Functionality
Key aspects of the preprocessing workflow available in our tool.
Supported Problem Types
3
Classification, regression, and time series analysis
Process Steps
4
Dataset upload, problem type, target selection, preprocessing
Auto-detection
2
Target column and dataset domain identification
Preprocessing Interface
Configure Your Data Preparation
Select from multiple imputation methods to handle missing values, choose appropriate encoding techniques for categorical variables, and apply the right scaling method for your numerical features. All preprocessing steps can be customized to match your specific dataset needs.
Try It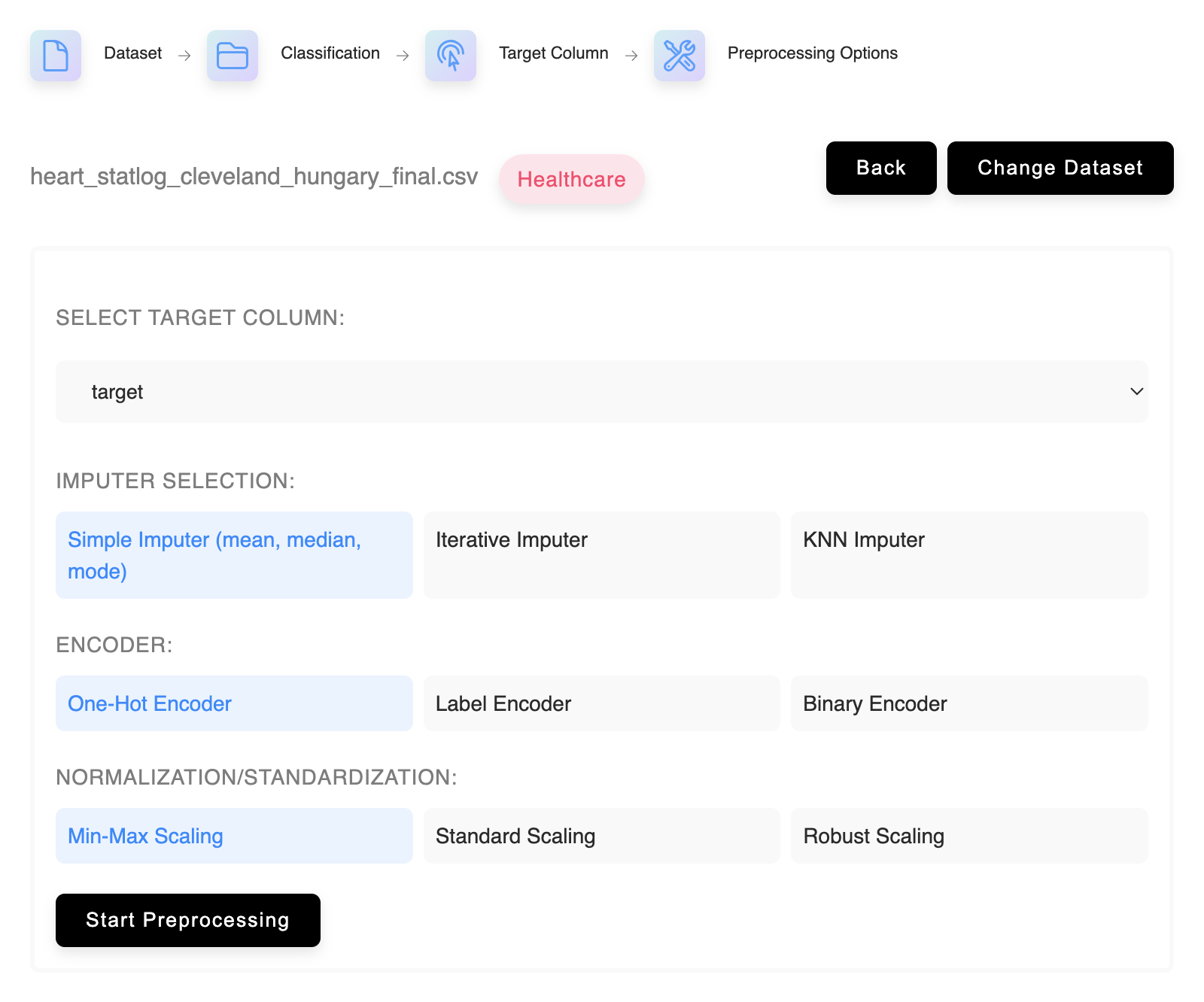
Raw Data Challenges
Missing values in datasets
Mixed data types requiring conversion
Inconsistent formats and scales
Categorical variables needing encoding
Processed Data Results
Complete datasets with filled missing values
Consistent data types ready for modeling
Normalized scales for better model performance
Properly encoded categorical variables
Practical Benefits
Increased
Model training efficiency
Data compatibility with algorithms
Accuracy of resulting models
Decreased
Time spent on manual data preparation
Technical barriers to creating ML models
Preprocessing errors and inconsistencies
Step-by-Step Process
Visual Preprocessing Pipeline
Our preprocessing workflow takes you through each transformation step, from raw data to ML-ready format. The system automatically identifies important characteristics of your dataset while allowing you to manually adjust parameters when needed.
Learn MoreData Preprocessing Pipeline
| A | ? | B | ? |
| 23 | 45 | ? | 34 |
| High | ? | Low | High |
Transformation Options
Available Preprocessing Methods
Core data transformation techniques available in the tool.



Available Techniques
Preprocessing Functions
Standard data preparation methods supported by the platform.
Missing Value Treatment
100%
Complete handling of null and missing data
Encoding Methods
3+
One-hot, label, and binary encoding options
Scaling Options
3+
Min-max, standard, and robust scaling